فرآیند علم داده

چرخه فرآیند علم داده
برای هر کدام از وظایفی که در حوزه علم داده انجام میشود و به منظور به دست آوردن نتایج مفید از دادهها، برخی از مراحل ضروری وجود دارد:
- جمعآوری دادهها: پس از تدوین یک بیانیه مشکل، کار اصلی جمعآوری دادههایی است که میتوانند در تحلیل و دستکاری کمک کنند. گاهی اوقات دادهها از طریق نظرسنجیها جمعآوری میشوند و در مواقعی دیگر از طریق فرآیندهایی مانند اسکرپینگ (scraping) دادهها انجام میشود.
- پاکسازی دادهها: بیشتر دادههای دنیای واقعی ساختارمند نیستند و قبل از استفاده در هرگونه تحلیل یا مدلسازی باید آنها را پاکسازی و به دادههای ساختارمند تبدیل کرد.
- تحلیل اکتشافی دادهها (EDA): این مرحله جایی است که تلاش میکنیم الگوهای پنهان در دادهها را پیدا کنیم. همچنین عوامل مختلفی که بر متغیر هدف تأثیر میگذارند و میزان تأثیر آنها را بررسی میکنیم. این مرحله به ما کمک میکند تا بفهمیم چگونه ویژگیهای مستقل به یکدیگر مرتبط هستند و چه کارهایی میتوانیم انجام دهیم تا به نتایج دلخواه دست یابیم.
- ساخت مدل: الگوریتمها و تکنیکهای مختلفی از یادگیری ماشین توسعه یافتهاند که میتوانند به راحتی الگوهای پیچیده در دادهها را شناسایی کنند، که این کار برای انسانها بسیار طاقتفرسا خواهد بود.
- پیادهسازی مدل: پس از اینکه مدلی توسعه یافت و نتایج بهتری در دادههای جداگانه (holdout) یا دادههای واقعی به دست آورد، مدل را پیادهسازی کرده و عملکرد آن را نظارت میکنیم. این مرحله جایی است که یادگیریهای خود را از دادهها به کاربردهای واقعی و استفادهها منتقل میکنیم.
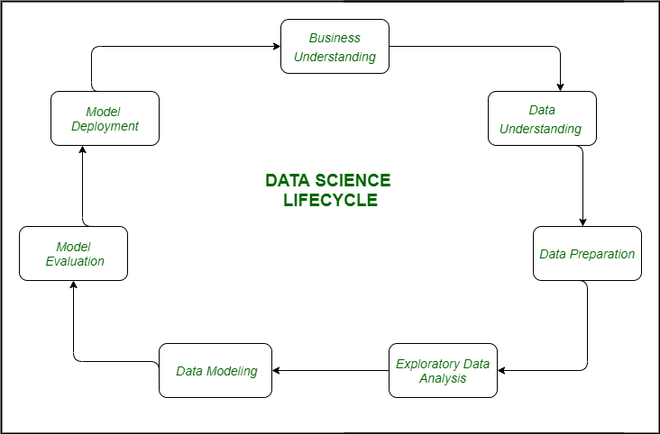
اجزای کلیدی فرآیند علم داده
علم داده یک حوزه بسیار گسترده است و برای دستیابی به بهترین نتایج از دادههای موجود باید از روشها و ابزارهای مختلفی استفاده کرد تا اطمینان حاصل شود که تمامیت دادهها در طول فرآیند حفظ میشود و حریم خصوصی دادهها رعایت میشود. اجزای اصلی فرآیند علم داده عبارتند از:
- تحلیل دادهها: گاهی اوقات نیازی به استفاده از روشهای پیچیده و یادگیری عمیق برای استخراج الگوها از دادهها نیست. بنابراین، پیش از شروع به مدلسازی، ابتدا تحلیل داده اکتشافی (EDA) انجام میدهیم تا تصویری ابتدایی از دادهها و الگوهای موجود در آنها به دست آوریم. این کار به ما جهتگیری میدهد تا در صورت نیاز به اعمال روشهای پیچیدهتر، از آنها بهرهبرداری کنیم.
- آمار: این یک پدیده طبیعی است که بسیاری از دادههای دنیای واقعی توزیع نرمال را دنبال میکنند. زمانی که میدانیم داده خاصی به یک توزیع شناخته شده تعلق دارد، بسیاری از ویژگیهای آن به سرعت قابل تحلیل خواهند بود. علاوه بر این، آمار توصیفی و همبستگیها و واریانس بین دو ویژگی در دادهها به ما کمک میکند تا درک بهتری از نحوه ارتباط عوامل مختلف با یکدیگر پیدا کنیم.
- مهندسی داده: هنگامی که با مقادیر زیادی از دادهها سر و کار داریم، باید اطمینان حاصل کنیم که دادهها در برابر تهدیدات آنلاین ایمن باشند و همچنین دسترسی به آنها آسان و امکان ایجاد تغییرات در آنها فراهم باشد. مهندسان داده در این زمینه نقش بسیار مهمی ایفا میکنند.
- محاسبات پیشرفته: در این بخش از علم داده، یادگیری ماشین و یادگیری عمیق نقشی حیاتی دارند.
- یادگیری ماشین: یادگیری ماشین افقهای جدیدی را گشوده است که به ما امکان ساخت برنامهها و روشهای پیشرفتهای را میدهد که کارها را بسیار سریعتر از آنچه که قبلاً توسط انسانها انجام میشد، انجام دهند.
- یادگیری عمیق: این بخش از هوش مصنوعی و یادگیری ماشین است که از آن پیچیدهتر است. قدرت محاسباتی بالا و حجم عظیم دادهها موجب ظهور این حوزه در علم داده شده است.
دانش و مهارتهای مورد نیاز برای حرفهایهای علم داده
برای تسلط بر علم داده و تبدیل شدن به یک متخصص در این زمینه، نیاز است که مجموعهای از مهارتها و دانشها را کسب کنید که شامل موارد زیر است:
- آمار:
- آمار بهعنوان مطالعه جمعآوری، تجزیهوتحلیل، تفسیر، ارائه و سازماندهی دادهها تعریف میشود. بنابراین، نباید تعجبآور باشد که دانشمندان داده باید آمار را بهخوبی بشناسند. آمار به ما کمک میکند تا دادهها را تحلیل کرده و از آنها بینشهای مفید استخراج کنیم.
- زبانهای برنامهنویسی (R/Python):
- پایتون و آر از رایجترین زبانهای برنامهنویسی در علم داده هستند. دلیل اصلی این امر، تعداد زیاد بستهها و کتابخانههایی است که برای محاسبات عددی و علمی در این زبانها وجود دارد.
- پایتون: با کتابخانههایی مانند Pandas، NumPy، SciPy، Matplotlib، Scikit-learn و TensorFlow برای تجزیهوتحلیل دادهها و یادگیری ماشین، بسیار محبوب است.
- آر: این زبان بهویژه در تحلیلهای آماری قوی است و کتابخانههایی مانند ggplot2، dplyr و caret برای مدلسازی و تجزیهوتحلیل دادهها در دسترس است.
- پایتون و آر از رایجترین زبانهای برنامهنویسی در علم داده هستند. دلیل اصلی این امر، تعداد زیاد بستهها و کتابخانههایی است که برای محاسبات عددی و علمی در این زبانها وجود دارد.
- استخراج، تبدیل و بارگذاری دادهها (ETL):
- فرآیند ETL شامل استخراج دادهها از منابع مختلف، تبدیل آنها به فرمت یا ساختار مناسب برای تحلیل، و بارگذاری دادهها در مخازن داده است. برای کسانی که در زمینه ETL تجربه دارند، علم داده میتواند یک مسیر شغلی مناسب باشد.
مراحل فرآیند علم داده
فرآیند علم داده شامل چندین مرحله است که برای دستیابی به نتایج موثر و دقیق از دادهها انجام میشود:
- تعریف مسئله و ایجاد منشور پروژه:
- اولین قدم در فرآیند علم داده، تعریف دقیق اهداف تحقیق است. منشور پروژه اهداف، منابع، نتایج مورد انتظار و زمانبندی پروژه را مشخص میکند تا اطمینان حاصل شود که همه ذینفعان همراستا و هماهنگ هستند.
- دریافت دادهها:
- دادهها معمولاً در پایگاههای داده، مخازن داده یا دریاچههای داده سازمانها ذخیره میشوند. دسترسی به این دادهها معمولاً شامل درخواست مجوزها و عبور از سیاستهای داخلی شرکت است.
- پاکسازی دادهها، یکپارچهسازی و تبدیل آنها:
- پاکسازی دادهها شامل حذف خطاها، ناسازگاریها و دادههای پرت است. یکپارچهسازی دادهها به ترکیب دادهها از منابع مختلف اشاره دارد و تبدیل دادهها فرآیندی است که دادهها را برای مدلسازی آماده میکند.
- تحلیل اکتشافی دادهها (EDA):
- در این مرحله، با استفاده از تکنیکهای گرافیکی مانند نمودار پراکندگی، هیستوگرامها و نمودار جعبهای، دادهها را برای شناسایی روندها و الگوهای موجود در آنها تجزیهوتحلیل میکنیم. این مرحله به انتخاب مدلسازی مناسب کمک میکند.
- ساخت مدلها:
- در این مرحله، مدلهای یادگیری ماشین یا یادگیری عمیق برای پیشبینی یا طبقهبندی دادهها ساخته میشوند. انتخاب الگوریتم به پیچیدگی مسئله و نوع دادهها بستگی دارد.
- ارائه نتایج و استقرار مدلها:
- پس از تکمیل تحلیلها، نتایج به ذینفعان ارائه میشود. مدلها به سیستمهای تولیدی منتقل میشوند تا تصمیمگیریها خودکار شوند یا به تحلیلهای جاری ادامه دهند.
مزایا و کاربردهای علم داده و دادههای کلان (Big Data)
- سازمانهای دولتی:
- سازمانهای دولتی به اهمیت دادهها پی بردهاند و از آنها در پروژههای مختلفی همچون شناسایی تقلب و دیگر فعالیتهای مجرمانه یا بهینهسازی تخصیص بودجه استفاده میکنند.
- سازمانهای غیردولتی (NGO):
- سازمانهای غیردولتی نیز به کاربرد دادهها واقف هستند و از آن برای جمعآوری کمک مالی و دفاع از اهداف خود بهره میبرند. بهعنوان مثال، WWF (Fund for World Wildlife) از دانشمندان داده برای بهبود کارایی تلاشهای جمعآوری کمکهای مالی خود استفاده میکند.
- دانشگاهها:
- دانشگاهها از علم داده برای تحقیقات خود و همچنین بهبود تجربه تحصیلی دانشجویان استفاده میکنند، مثلاً از طریق دورههای آموزشی آنلاین گسترده (MOOC).
ابزارهای رایج در فرآیند علم داده
با پیشرفت زمان، ابزارهای مختلفی برای انجام فعالیتهای مختلف در علم داده توسعه یافتهاند. ابزارهایی مانند Matlab و Power BI و زبانهای برنامهنویسی پایتون و آر ویژگیهای بسیاری را برای انجام وظایف پیچیده در زمان محدود فراهم میکنند.
برخی از ابزارهای محبوب در این حوزه عبارتند از:
- Matlab برای محاسبات عددی و تحلیل دادهها.
- Power BI برای ایجاد داشبوردها و گزارشهای تعاملی.
- Python و R برای تجزیهوتحلیل دادهها، مدلسازی و یادگیری ماشین.

استفاده از فرآیند علم داده
فرآیند علم داده یک رویکرد سیستماتیک برای حل مسائل مرتبط با دادهها است و شامل مراحل زیر میباشد:
- تعریف مسئله:
- در این مرحله، مسئله بهطور واضح تعریف میشود و هدف تحلیل مشخص میشود.
- جمعآوری دادهها:
- در این مرحله، دادهها از منابع مختلف جمعآوری میشوند که شامل پاکسازی و آمادهسازی دادهها نیز میشود.
- اکتشاف دادهها:
- دادهها بهطور دقیق بررسی میشوند تا بینشهایی بهدست آید و روندها، الگوها و روابط موجود شناسایی شوند.
- مدلسازی دادهها:
- در این مرحله، مدلهای ریاضی و الگوریتمها ساخته میشوند تا مسائل حل شوند و پیشبینیهایی انجام گیرد.
- ارزیابی:
- عملکرد و دقت مدل ارزیابی میشود و از معیارهای مناسب برای سنجش کیفیت مدل استفاده میشود.
- استقرار:
- مدل در محیط تولید مستقر میشود تا پیشبینیهایی انجام دهد یا فرآیندهای تصمیمگیری را خودکار کند.
- نظارت و نگهداری:
- عملکرد مدل در طول زمان نظارت میشود و بهطور مداوم بهروزرسانیهایی برای بهبود دقت انجام میشود.
چالشها در فرآیند علم داده
- کیفیت و در دسترس بودن دادهها:
- کیفیت دادهها میتواند بر دقت مدلهای توسعهیافته تأثیر بگذارد، بنابراین مهم است که دادهها دقیق، کامل و سازگار باشند. همچنین، در دسترس بودن دادهها میتواند یک چالش باشد، زیرا دادههای مورد نیاز ممکن است بهراحتی در دسترس نباشند.
- تعصب در دادهها و الگوریتمها:
- تعصب میتواند در دادهها وجود داشته باشد که به دلیل تکنیکهای نمونهبرداری، خطاهای اندازهگیری یا مجموعه دادههای نامتعادل رخ میدهد. این میتواند دقت مدلها را تحتتأثیر قرار دهد. الگوریتمها نیز میتوانند تعصبات موجود در جامعه را تقویت کرده و منجر به نتایج ناعادلانه یا تبعیضآمیز شوند.
- شکست مدل (Overfitting) و عدم انطباق مدل (Underfitting):
- Overfitting زمانی رخ میدهد که مدل خیلی پیچیده باشد و بهطور دقیق بر دادههای آموزشی فیت شود، اما نتواند بر دادههای جدید تعمیم پیدا کند.
- Underfitting زمانی رخ میدهد که مدل خیلی ساده باشد و قادر به شبیهسازی روابط زیرین در دادهها نباشد.
- قابلیت تفسیر مدل:
- مدلهای پیچیده میتوانند دشوار برای تفسیر و درک باشند، که این موضوع میتواند چالشهایی را در توضیح تصمیمات مدل ایجاد کند. این میتواند در هنگام اتخاذ تصمیمات تجاری یا جلب حمایت ذینفعان یک مشکل ایجاد کند.
- مسائل حریم خصوصی و اخلاقی:
- علم داده اغلب شامل جمعآوری و تحلیل اطلاعات شخصی حساس است که منجر به نگرانیهای حریم خصوصی و اخلاقی میشود. بسیار مهم است که به تأثیرات حریم خصوصی توجه شده و اطمینان حاصل شود که دادهها بهصورت مسئولانه و اخلاقی استفاده میشوند.
نتیجهگیری
فرآیند علم داده یک رویکرد چرخهای و تکراری است که معمولاً به مراحل اولیه بازمیگردد زمانی که بینشها و چالشهای جدید نمایان میشوند. این فرآیند شامل تعریف یک مسئله، جمعآوری و آمادهسازی دادهها، بررسی و مدلسازی آنها، استقرار مدل و بهبود مستمر آن در طول زمان است. ارتباط نتایج برای اتخاذ تصمیمات مبتنی بر دادهها بسیار مهم است.



دیدگاهتان را بنویسید